
内存管理
1 物理内存
Linux 内存的最小单位为页,一页通常是4K,初始化时,linux 会为每个物理内存建立一个page的管理结构,操作物理内存时 实际上就是操作page。
2 进程内存
Linux 进程是通过vma进行管理的,每一个进程都有一个task_struct 结构体进行维护,其中mm_struct结构体管理进程内的所有内存。mm_struct 的结构如下
1 | struct mm_struct { |
可以看到 mm_struct 中有个vma链表,其中每个vma节点对应一段连续内存,(在进程的虚拟地址空间是连续的,物理空间中不一定)。当使用malloc 申请内存时,内核会给进程增加vma节点。
对于32位的linux 操作系统,为每一个进程分配的寻址空间都是4g,linux将这4g的虚拟内存分为两部分
- 用户空间 0-3g
- 内核空间 3-4g
用户空间和内核空间
linux将 进程虚拟地址中的0-3g空间 用作用户空间.
为什么会有用户控件和内核空间的划分
是为了将用户空间与内核空间区分开,为了访问安全
Linux使用两级保护机制:0级供内核使用,3级供用户程序使用。每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的。如果要访问内核空间,会有优先级的限制从而在一定程度上保护了内核空间的安全性。
为什么会按照内核空间1g,用户空间3g来划分。
这个比例其实并不是固定的,它可以是一个人为设定值,可以通过重新编译linux内核来实现更改。
进程只分配了4g虚拟内存,如果物理内存大于4g,如何做到访问其余的内存呢
这里涉及到高端地址的概念了
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射,如果将内核空间的1g内存全部做线性映射【注1】,那么当物理内存为8g的时候,剩下的4g内存将无法被访问到。为了解决这个问题,linux将内核空间分为了3部分
ZONE_DMA内存开始的16MBZONE_NORMAL16MB~896MBZONE_HIGHMEM896MB ~ 结束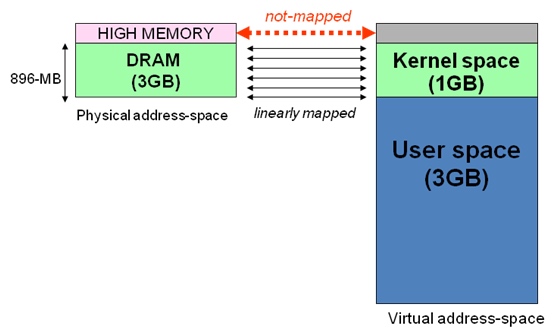
可以看到,低dma 和 normal 内存区与物理内存做了线性映射。
但是高端内存(最上面的128m)并未与物理内存进行线性映射,事实上,linux正是借助这小块高端内存 才做到了用128m 访问剩余4g物理内存的。
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。如下图。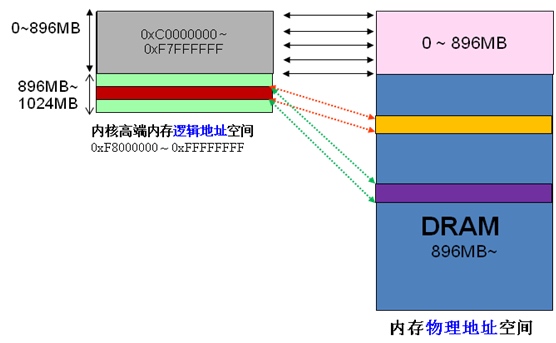
从上面的描述,我们可以知道高端内存的最基本思想:借一段地址空间,建立临时地址映射,用完后释放,达到这段地址空间可以循环使用,访问所有物理内存。
注1:线性映射与非线性映射:
Linux内核只有1G的空间,通常内核把物理内存与其地址空间做了线性映射,也就是一一映,这样可以提高内存访问速度。
当内存超过1G时,线性访问机制就不够用了,只能有1G的内存可以被映射,剩余的内存无法被内核使用。当然无法忍受。
为了解决这一问题,linux把内核分为线性区与非线性区两部分。线性区规定最大为896M,剩下的为非线性区。与线性区不同,非线性区不会提前进行内存映射,而是在使用时动态映射。线性区映射的物理内存成为低端内存,剩下的内存被称为高端内存。
假设物理内存为2G,则地段的896M为低端内存,通过线性映射给内核使用。其他的1128M内存为高端内存,可以被内核的非线性区使用。由于要使用128M非线性区来管理超过1G的高端内存,所以通常都不会映射,只有使用时才使kmap映射,使用完后要尽快用kunmap释放。
对于物理内存为1G的内核,系统不会真的分配896M给线性空间,896M最大限制。下面是一个1.5G物理内存linux系统的真实分配情况,只有721M分配给了低端内存区,如果是1G的linxu系统,分配的就更少了。
1 | MemTotal 1547MB |
申请高端内存时,如果高端内存不够了,linux也会去低端内存区申请,反之则不行。
内核空间被所有进程共享,那么进程里的内核空间都是一样的吗?
是的,进程里的内核空间都是一样的。
Linux启动后,第一个进程是init进程,它的页表与内核页表是一致的,系统中的其他所有进程都是init进程的儿子或后代。Linux中进程创建通过fork()实现,子进程的PGD(进程页目录)与PTE(进程页表项,里面记录了具体的物理地址)是父进程的拷贝此时会把内核进程的页表拷贝到每个进程中。在各个进程的运行过程中,他们的页表可能会发生变化,比如发生缺页异常。如果是进程页表发生改变,则只要改变进程的页表项(0G~3G)就够了,如果是内核页表发生变化,则必须通知到所有进程改变各自维护的一份内核页表(3G~4G)。最简单的方法是每次内核页表改变后,遍历所有进程去改变他们维护的内核页表,显然效率很低。Linux内核通过page fault机制实现内核页表的一致。
内核页表改变时,只改变init进程的内核页表。当进程访问该页时,会发生一个缺页异常,异常处理中通过init进程更新当前进程的内核页表。
进程的内核空间都是一样的,那为什么要把每个进程的内核空间都拷贝一份,不可以进程的虚拟地址只有进程空间,而所有内核空间单独只维持一份吗?
目的其实很简单,为了减少内核调用的系统开销。
我们常说,切换线程和切换进程相比,进程切换的开销更大,是因为每一个进程都对应着一个进程页表,切换进程会对应页表的切换,线程因为在同一个进程里,很多资源是共享的,切换线程(其实linux里 线程与进程是同一个东西,切换线程也对应页表的切换,只不过页表内容没有变而已)相当于只切换一些上下文。
从问题中提出的两个方式来考虑开销问题。
- 每个进程使用独立页表 (当前内核的做法)
- 所有进程在内核态使用同一页表,但用户态每进程使用独立页表
考虑两个场景
- 场景1:用户态切陷入内核态采用方案1),进程从用户态陷入内核态时(系统调用,中断都可触发),不需要切换页表;采用方案2),用户态陷入内核态时,需要切换页表。并且进入内核态时,根据没有跳板(一段专代码)来完成切换,因为内核地址空间在切换之后根本没有映射。
- 场景2:任务切换如果进程跑在用户态,来了中断,陷入内核态,然后任务切换。 方案1)在陷入内核态时有一次页表切换;方案2)在任务切切换有一次页表切换。两者打平手。但通常任务切换之后,新任务也要回到用户态的,那方案1)又会引入一次页切换。在程序的实际运行过程中,程序调用系统调用的次数比任务切换的次数多,所以方案1)远比方案2)有优势。
地址转换
一张图解释 用户空间 内核空间 物理地址的转换关系
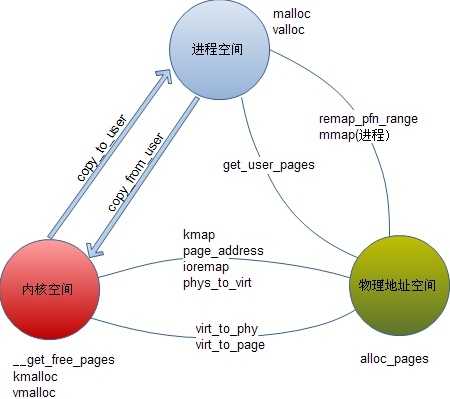
在linux中,物理地址用page结构 表示,物理内存在初始化时已经生成了page结构管理,其他地址空间则需要生成page再进行管理(ioremap)。物理地址可以被映射到内核空间或进程空间,也可以从内核空间或进程用户空间解除物理地址(page)。
所有转换中,只有mmap可以在进程中使用,其他都是内核函数。即使使用mmap,其内部也是靠内核中使用remap_pfn_range实现的。所有地址空间转换都在内核中实现。