
FD 文件描述符
一、概念
Linux 系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来指向被打开的文件,所有执行I/O操作的系统调用都会通过文件描述符。
二、文件描述符、文件、进程间的关系
1.描述:
我们可以通过linux的几个基本的I/O操作函数来理解什么是文件操作符。
1 | fd = open(pathname, flags, mode) |
每当进程用open()函数打开一个文件,内核便会返回该文件的文件操作符(一个非负的整形值),此后所有对该文件的操作,都会以返回的fd文件操作符为参数。【注1】
注1: 文件描述符可以理解为进程文件描述表这个表的索引,或者把文件描述表看做一个数组的话,文件描述符可以看做是数组的下标。当需要进行I/O操作的时候,会传入fd作为参数,先从进程文件描述符表查找该fd对应的那个条目,取出对应的那个已经打开的文件的句柄,根据文件句柄指向,去系统fd表中查找到该文件指向的inode,从而定位到该文件的真正位置,从而进行I/O操作。
每个文件描述符会与一个打开的文件相对应
不同的文件描述符也可能指向同一个文件
相同的文件可以被不同的进程打开,也可以在同一个进程被多次打开
2.系统为维护文件描述符,建立了三个表
进程级的文件描述符表
系统级的文件描述符表
文件系统的i-node表 (inode 见下文)
进程级别的文件描述表:
linux内核会为每一个进程创建一个task_truct结构体来维护进程信息,称之为 进程描述符,该结构体中 指针 1
struct files_struct *files
指向一个名称为file_struct的结构体,该结构体即 进程级别的文件描述表。
它的每一个条目记录的是单个文件描述符的相关信息
- fd控制标志,前内核仅定义了一个,即close-on-exec
- 文件描述符所打开的文件句柄的引用【注2】
[注释2]:文件句柄这里可以理解为文件名,或者文件的全路径名,因为linux文件系统文件名和文件是独立的,以此与inode区分
系统级别的文件描述符表
内核对系统中所有打开的文件维护了一个描述符表,也被称之为 【打开文件表】,表格中的每一项被称之为 【打开文件句柄】,一个【打开文件句柄】 描述了一个打开文件的全部信息。
主要包括:
- 当前文件偏移量(调用read()和write()时更新,或使用lseek()直接修改)
- 打开文件时所使用的状态标识(即,open()的flags参数)
- 文件访问模式(如调用open()时所设置的只读模式、只写模式或读写模式)
- 与信号驱动相关的设置
- 对该文件i-node对象的引用
- 文件类型(例如:常规文件、套接字或FIFO)和访问权限
- 一个指针,指向该文件所持有的锁列表
- 文件的各种属性,包括文件大小以及与不同类型操作相关的时间戳
Inode表
每个文件系统会为存储于其上的所有文件(包括目录)维护一个i-node表,单个i-node包含以下信息:
- 文件类型(file type),可以是常规文件、目录、套接字或FIFO
- 访问权限
- 文件锁列表(file locks)
- 文件大小
等等
i-node存储在磁盘设备上,内核在内存中维护了一个副本,这里的i-node表为后者。副本除了原有信息,还包括:引用计数(从打开文件描述体)、所在设备号以及一些临时属性,例如文件锁。
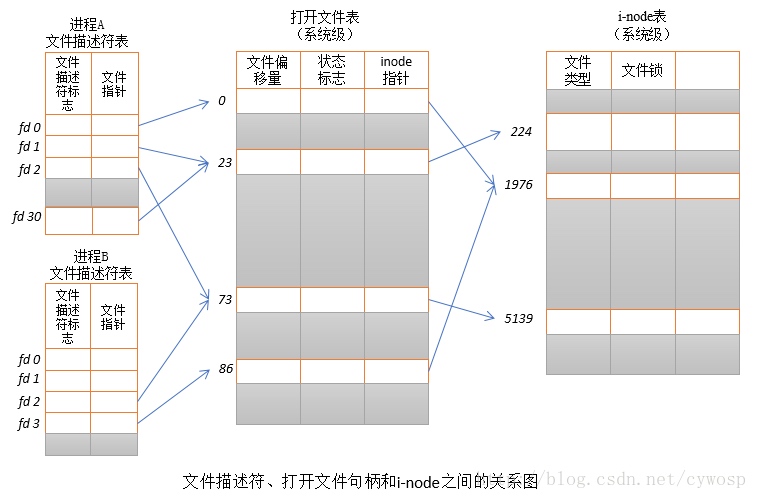
注:进程A的fd表中,左边fd0,fd1,fd2… 就是各个文件描述符,它是fd表的索引,fd不是表里那个fd flags!这里不要搞混淆了,fd flags 目前只有一个取值。
在进程A中,文件描述符1和30都指向了同一个打开的文件句柄(标号23)。这可能是通过调用dup()、dup2()、fcntl()或者对同一个文件多次调用了open()函数而形成的。
dup(),也称之为文件描述符复制函数,在某些场景下非常有用,比如:标准输入/输出重定向。在shell下,完成这个操作非常简单,大部分人都会,但是极少人思考过背后的原理。
大概描述一下需要的几个步骤,以标准输出(文件描述符为1)重定向为例:
- 打开目标文件,返回文件描述符n;
- 关闭文件描述符1;
- 调用dup将文件描述符n复制到1;
- 关闭文件描述符n;
进程A的文件描述符2和进程B的文件描述符2都指向了同一个打开的文件句柄(标号73)。这种情形可能是在调用fork()后出现的(即,进程A、B是父子进程关系)【注3】,或者当某进程通过UNIX域套接字将一个打开的文件描述符传递给另一个进程时,也会发生。再者是不同的进程独自去调用open函数打开了同一个文件,此时进程内部的描述符正好分配到与其他进程打开该文件的描述符一样。
注3: 子进程会继承父进程的文件描述符表,也就是子进程继承父进程打开的文件 这句话的由来。
此外,进程A的描述符0和进程B的描述符3分别指向不同的打开文件句柄,但这些句柄均指向i-node表的相同条目(1976),换言之,指向同一个文件。发生这种情况是因为每个进程各自对同一个文件发起了open()调用。同一个进程两次打开同一个文件,也会发生类似情况。
三、文件描述符限制
有资源的地方就有战争,“文件描述符”也是一种资源,系统中的每个进程都需要有“文件描述符”才能进行改变世界的宏图霸业。世界需要秩序,于是就有了“文件描述符限制”的规定。
如下表: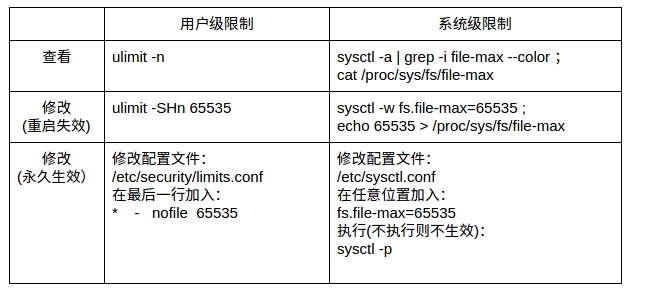
永久修改用户级限制时有三种设置类型:
soft 指的是当前系统生效的设置值
hard 指的是系统中所能设定的最大值
“-” 指的是同时设置了 soft 和 hard 的值
Inode 文件节点
一、inode是什么?
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做”扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。这种由多个扇区组成的”块”,是文件存取的最小单位。”块”的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在”块”中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点”。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
二、inode的内容
inode包含文件的元信息,具体来说有以下内容:
- 文件的字节数
- 文件拥有者的User ID
- 文件的Group ID
- 文件的读、写、执行权限
- 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
- 链接数,即有多少文件名指向这个inode
- 文件数据block的位置
可以用stat命令,查看某个文件的inode信息:
stat 233.txt

总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
三、inode的大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令。
df -i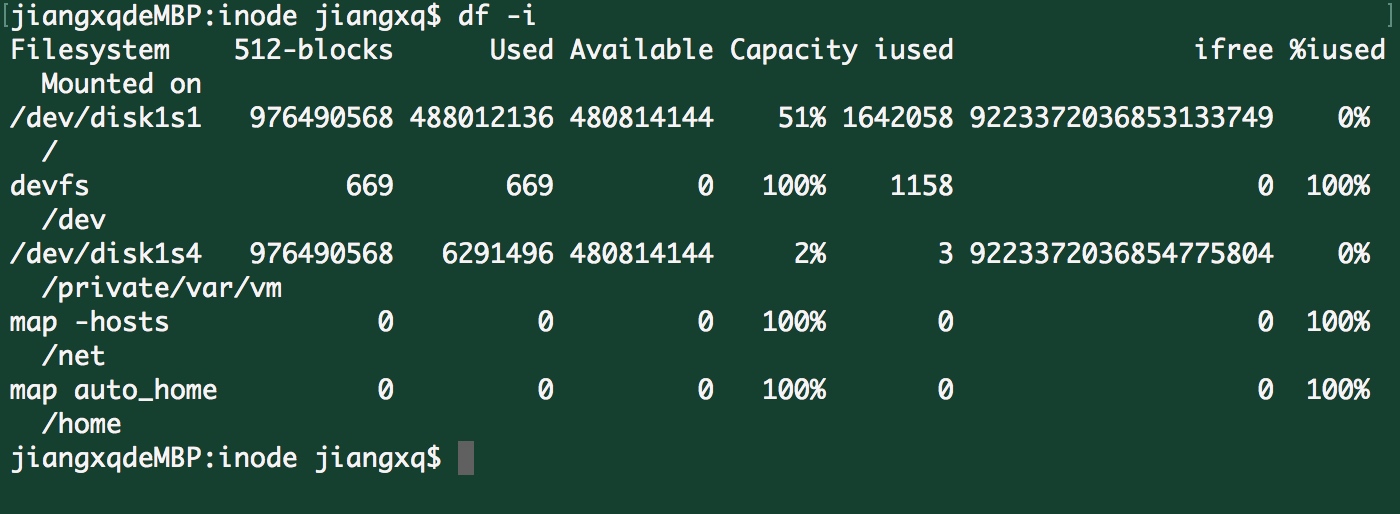
查看每个inode节点的大小,可以用如下命令:
sudo dumpe2fs -h /dev/hda | grep "Inode size"
由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
四、inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
这里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
使用ls -i命令,可以看到文件名对应的inode号码:
ls -i 233.txt

五、目录文件
Unix/Linux系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。
目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
ls命令只列出目录文件中的所有文件名:
ls /etc
ls -i命令列出整个目录文件,即文件名和inode号码:
ls -i /etc
如果要查看文件的详细信息,就必须根据inode号码,访问inode节点,读取信息。ls -l命令列出文件的详细信息。
ls -l /etc
理解了上面这些知识,就能理解目录的权限。目录文件的读权限(r)和写权限(w),都是针对目录文件本身。由于目录文件内只有文件名和inode号码,所以如果只有读权限,只能获取文件名,无法获取其他信息,因为其他信息都储存在inode节点中,而读取inode节点内的信息需要目录文件的执行权限(x)。
六、硬链接
一般情况下,文件名和inode号码是”一一对应”关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。
这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为”硬链接”(hard link)。
ln命令可以创建硬链接:
ln 源文件 目标文件
运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做”链接数”,记录指向该inode的文件名总数,这时就会增加1。
反过来,删除一个文件名,就会使得inode节点中的”链接数”减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的”链接数”。创建目录时,默认会生成两个目录项:”.”和”..”。前者的inode号码就是当前目录的inode号码,等同于当前目录的”硬链接”;后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的”硬链接”。所以,任何一个目录的”硬链接”总数,总是等于2加上它的子目录总数(含隐藏目录)。
七、软链接
除了硬链接以外,还有一种特殊情况。
文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的”软链接”(soft link)或者”符号链接(symbolic link)。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:”No such file or directory”。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode”链接数”不会因此发生变化。
ln -s命令可以创建软链接。
ln -s 源文文件或目录 目标文件或目录
八、inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
移动文件或重命名文件,只是改变文件名,不影响inode号码。
打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。