前言
在读apue第八章进程控制时, 看到一段很有意思的代码:
“如果一个进程fork一个子进程,但不要他等待子进程终止,也不希望子进程处于僵死状态知道父进程终止,实现这一要求的诀窍是调用fork两次。”
实例代码如下:
1 |
|
为了解释这个问题 先说明一下fork函数是怎么运作的
fork后子进程从何处开始执行
为了说明这个问题 先看一个例子
1 |
|
一个进程,主要包含三个元素:
- 一个可以执行的程序; — 代码段
- 和该进程相关联的全部数据(包括变量,内存空间,缓冲区等等); — 数据段
程序的执行上下文(execution context)。 — 堆栈段
“代码段”,顾名思义,就是存放了程序代码的数据,假如机器中有数个进程运行相同的一个程序,那么它们就可以使用相同的代码段。“堆栈段”存放的就是子程序的返回地址、子程序的参数以及程序的局部变量。而数据段则存放程序的全局变量,常数以及动态数据分配的数据空间(比如用malloc之类的函数取得的空间)。一般的CPU都有上述三种段寄存器,以方便操作系统的运行。
这三个部分也是构成一个完整的执行序列的必要的部分。系统如果同时运行数个相同的程序,它们之间就不能使用同一个堆栈段和数据段。
当程序执行到下面的语句:
pid=fork();
操作系统创建一个新的进程(子进程),并且在进程表中相应为它建立一个新的表项。
新进程和原有进程的可执行程序是同一个程序;上下文和数据,绝大部分就是原进程(父进程)的拷贝,但它们是两个相互独立的进程!此时程序寄存器pc,在父、子进程的上下文中都声称,这个进程目前执行到fork调用即将返回(此时子进程不占有CPU,子进程的pc不是真正保存在寄存器中,而是作为进程上下文保存在进程表中的对应表项内)。问题是怎么返回。它们的返回顺序是不确定的,取决于OS内的调度。如果想明确它们的执行顺序,就得实现“同步”,或者是使用vfork()。这里假设父进程继续执行,操作系统对fork的实现,使这个调用在父进程中返回刚刚创建的子进程的pid(一个正整数),所以下面的if语句中pid<0, pid==0的两个分支都不会执行。所以一般执行fork后都会有两个输出。
再看上面的例子
对于上面程序段有以下几个关键点:
返回值的问题:
正确返回: 父进程中返回子进程的pid,因此> 0;子进程返回0
错误返回: -1
子进程是父进程的一个拷贝。即,子进程从父进程得到了数据段和堆栈段的拷贝,这些需要分配新的内存;而对于只读的代码段,通常使用共享内存的方式访问。父进程与子进程的不同之处在于:fork的返回值不同——父进程中的返回值为子进程的进程号,而子进程为0。只有父进程执行的getpid()才是他自己的进程号。对子进程来说,fork返回给它0,但它的pid绝对不会是0;之所以fork返回0给它,是因为它随时可以调用getpid()来获取自己的pid;
fork返回后,子进程和父进程都从调用fork函数的下一条语句开始执行。
这也是程序中会打印两个结果的原因。
fork之后,操作系统会复制一个与父进程完全相同的子进程。不过这在操作系统看来,他们更像兄弟关系,这2个进程共享代码空间,但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,但只有一点不同,如果fork成功,子进程中fork的返回值是0,父进程中fork的返回值是子进程的进程号,如果fork不成功,父进程会返回错误。2个进程一直同时运行,而且步调一致,在fork之后,他们分别作不同的工作,也就是分岔了。这也是fork为什么叫fork的原因。至于哪一个先运行,与操作系统的调度算法有关,而且这个问题在实际应用中并不重要,如果需要父子进程协同,可以通过原语的办法实现同步来加以解决。
再回看为何fork两次 可以消除僵尸进程
逐行来分析代码
1 | // 存储进程号相关信息 |
附录
看到有网友画的几张进程处于不同状态的图,挺直观的,贴上以作保存。
孤儿进程
孤儿进程是指父进程在子进程结束之前死亡(return 或exit)。如下图所示:
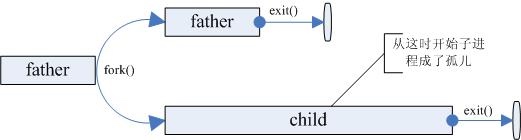
但是孤儿进程并不会像上面画的那样持续很长时间,当系统发现孤儿进程时,init进程就收养孤儿进程,成为它的父亲,child进程exit后的资源回收就都由init进程来完成。
僵尸进程
僵尸进程是指子进程在父进程之前结束了,但是父进程没有用wait或waitpid回收子进程。如下图所示: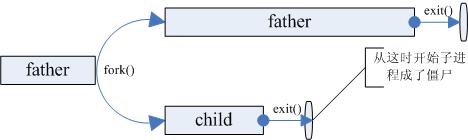
父进程没有用wait回收子进程并不说明它不会回收子进程。子进程在结束的时候会给其父进程发送一个SIGCHILD信号,父进程默认是忽略SIGCHILD信号的,如果父进程通过signal()函数设置了SIGCHILD的信号处理函数,则在信号处理函数中可以回收子进程的资源。
事实上,即便是父进程没有设置SIGCHILD的信号处理函数,也没有关系,因为在父进程结束之前,子进程可以一直保持僵尸状态,当父进程结束后,init进程就会负责回收僵尸子进程。
但是,如果父进程是一个服务器进程,一直循环着不退出,那子进程就会一直保持着僵尸状态。虽然僵尸进程不会占用任何内存资源,但是过多的僵尸进程总还是会影响系统性能的。黔驴技穷的情况下,该怎么办呢?
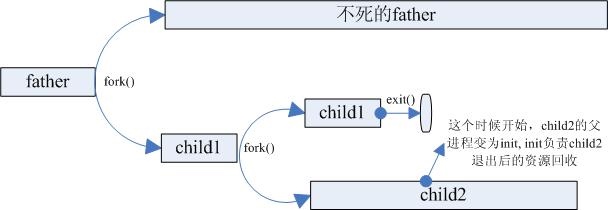
这个时候就需要一个英雄来拯救整个世界,它就是两次fork()技法。
两次fork()技法
两次fork()的流程如下所示: